
- 티스토리 목차
- magic command
- 티스토리 자동 목차
- tistory toc
- matplotlib 객제 지향 방식
- NewYork Times 읽기
- fig ax 사용
- tistory 목차
- jupyter notebook shell commands
- TOC
develop myself
데이터 핸들링: 데이터 재구성해서 보기 본문
df.groupby().func()
| 집계 | 설명 |
|---|---|
count |
전체 개수 |
head, tail |
앞의 함목 일부 반환, 뒤의 항목 일부 반환 |
describe |
Series, DataFrame의 각 컬럼에 대한 요약 통계 |
min, max |
최소값, 최대값 |
cummin, cummax |
누적 최소값, 누적 최대값 |
argmin, argmax |
최소값과 최대값의 색인 위치 |
idxmin, idxmax |
최소값과 최대값의 색인값 |
mean, median |
평균값, 중앙값 |
std, var |
표준편차(Standard deviation), 분산(Variance) |
skew |
왜도(skewness) 값 계산 |
kurt |
첨도(kurtosis) 값 계산 |
mad |
절대 평균 편차(Mean Absolute Deviation) |
sum, cumsum |
전체 항목 합, 누적합 |
prod, cumprod |
전체 항목 곱, 누적곱 |
quantile |
0부터 1까지의 분위수 계산 |
diff |
1차 산술차 계산 |
pct_change |
퍼센트 변화율 계산 |
corr, cov |
상관관계, 공분산 계산 |
pd.crosstab()
두 개의 기준에 따른 데이터의 분포를 확인할 때
iris = load_iris()
iris_df = pd.DataFrame(data=iris.data, columns=iris.feature_names)
iris_df['class'] = iris.target
iris_df['class'] = iris_df['class'].map({i:iris.target_names[i] for i in list(set(iris.target))})
iris_df
iris_df['petal width level'] = pd.qcut(iris_df['petal width (cm)'], q=3, labels=['short','middle','long'])
pd.crosstab(iris_df['petal width level'], iris_df['class'])
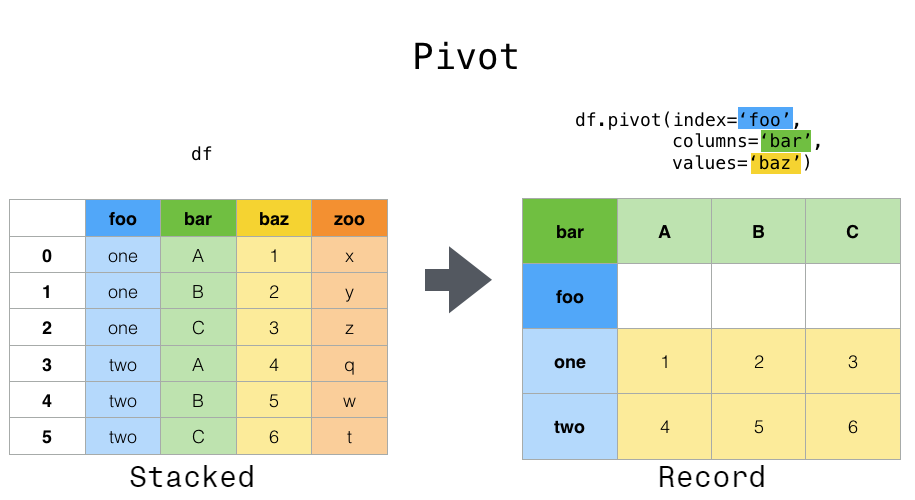
df.pivot()
일반적인 목적의 pivot, 다양한 데이터 타입(문자열, 숫자 등)에 대하여 pivot을 진행한다. (집계 기능 없음)
- `df.pivot(index=, columns=, values=)
- index: 피벗 테이블에서 인덱스가 될 컬럼의 이름(두 개 이상이면 리스트로 입력)
- columns: 피벗 테이블에서 컬럼으로 분리할 컬럼의 이름(범주형 변수 사용)
- values: 피벗 테이블에서 columns의 값이 될 컬럼의 이름
df.pivot_table()
집계 기능을 추가한 pivot.
- df.pivot_table(index=None, columns=None, values=None, aggfunc='mean')
- index: 피벗 테이블에서 인덱스가 될 컬럼의 이름(두 개 이상이면 리스트로 입력)
- columns: 피벗 테이블에서 컬럼으로 분리할 컬럼의 이름(범주형 변수 사용)
- values: 피벗 테이블에서 columns의 값이 될 컬럼의 이름
- aggfunc: 집계함수를 사용할 경우 지정
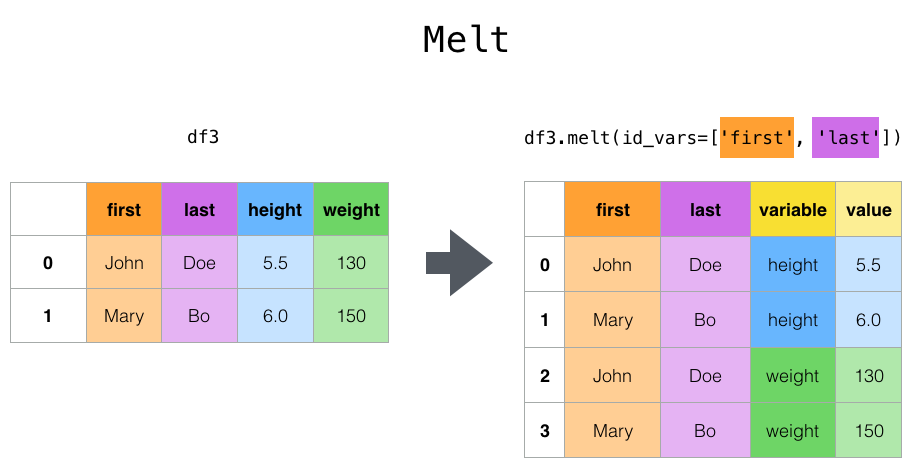
df.melt()
- pivot_table의 반대
- `df.melt(id_vars=None, var_name=None, value_name=None)
- id_vars: 피벗 테이블에서 인덱스가 될 컬럼의 이름(variable, value의 내용으로 들어가지 않을 컬럼의 이름 리스트)
- var_name: variable 변수의 이름으로 지정할 문자열(선택)
- value_name: value 변수의 이름으로 지정할 문자열(선택)
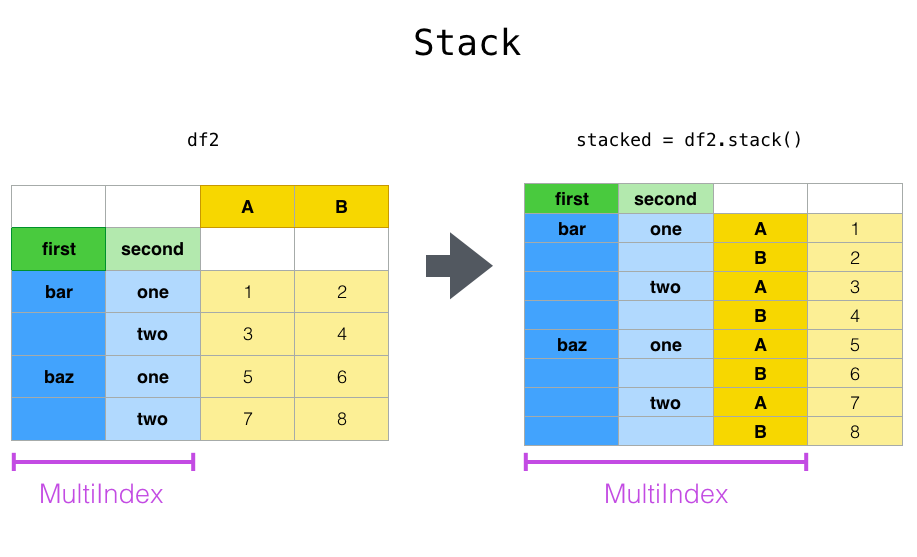
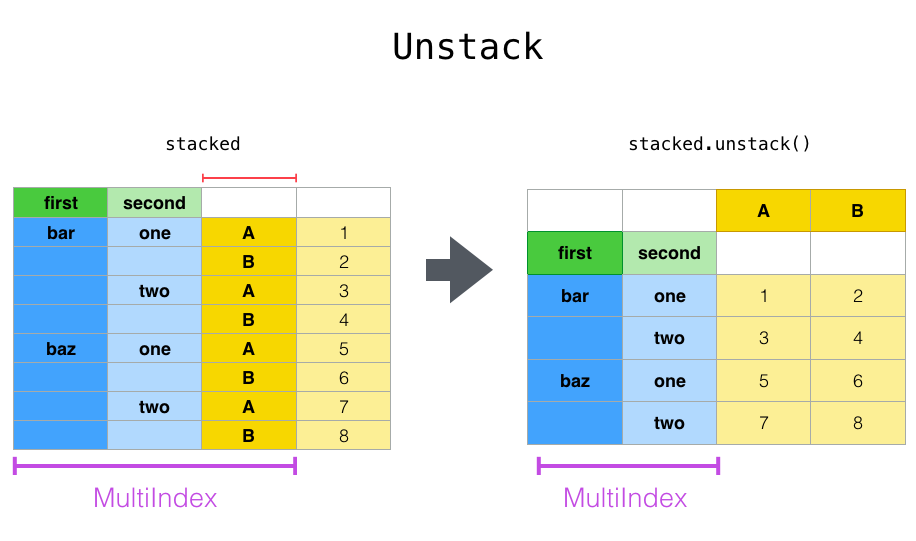
df.stack(), df.unstack()
참고
- pandas official: https://pandas.pydata.org/docs/user_guide/reshaping.html
- 이수안컴퓨터연구소 pandas 한번에 끝내기: https://youtu.be/lG8pEwvYwCw
- 책: 파이썬 한권으로 끝내기 데이터분석전문가(ADP) + 빅데이터분석기사 실기대비
'DataScience > Python' 카테고리의 다른 글
| matplotlib 사용 지침 (0) | 2023.01.27 |
|---|---|
| 데이터핸들링: 문자열(str) (0) | 2023.01.27 |
| 데이터 핸들링: 기본 (0) | 2023.01.27 |
| matplotlib cheatsheets, handout (0) | 2023.01.26 |
| matplotlib basic tips (0) | 2023.01.26 |
